What We Can and Cannot Take Away From Clinical Studies Regarding Investments; A Generalization
One such discipline is clinical studies (props to Kelvin for the article). A number of papers have dived into comparisons of the two, making clear that much of the estimation currently done in the medical field by doctors and the like should actually probably be made through actuarial methods. The bottom line, it seemed, was that actuarial methods dominate their clinical counterparts in almost every study that has been performed. The tests usually consist of assessing the probability of having a machine and a clinician make a judgement about the nature of a person's illness given the same dataset, and comparing the respective frequencies. Even when clinicians are given an informational advantage, they still don't beat their machine counterpart. In many cases, the new information doesn't help them at all.
I would encourage people read some of the findings-- it's really interesting stuff! But before everyone goes off and becomes quants there are a few things that should be noted; the caveat is that investing is not the same as making a handful of prognoses at a hospital.
- Unlike in a hospital setting where everyone needs to get diagnosed (deferring judgement isn't an option), investors have the liberty to avoid that which they have no "edge" on. Charlie Munger comes to mind. In some ways he does precisely the opposite of what the clinician is told to do. He sits on his hands and waits until he sees what he perceives to be a huge opportunity and he puts on a position in size. Market making is another story.
- Incidentally, this is why I think many rapid fire trading strategies tend to be short vol. Processes assume a certain set of statistical properties until they don't. Shocks to the system and regime shifts don't lend themselves well to automated models, which might have a difficult time assessing when it's time to re-evaluate the model. I would tend to say along these lines that Charlie Munger's methodology is long vol.
- Liquidity removes some of the comparability between the two fields. In some sense I guess there is no liquidity in the medical world-- you make the choice, then are subject to a binary outcome-- yes or no. In the markets it has implications on competition and hence efficiency, transaction costs, market impact, etc.
That being said, some of the criticisms of clinician's assessments reminds me very strongly of the psychological biases subject to investors. Overconfidence when it isn't merited (being Fooled By Randomness), viewing historical events as more causal and less random than they actually were, the phenomenon of being flooded by data to the point that judgement is actually impeded, misconceived disdain for aggregate statistics, improper and randomly varying factor weighting... these are universal decision making problems.
Given the nature of the decisions being made by clinicians, it makes a lot of sense to me that a quantitative framework is more appropriate. That being said, I don't believe the same is necessarily true of the financial markets. Or perhaps I am being fooled by personal bias :)
-Dan
ps. In the same way that one goes about increasing ones information set by looking at comparable situations, the same can be said of stocks. Of course we all know the age old trick of looking at comps. I'm actually referring to estimating "comparability" by whipping out the time series of a stock with every other stock in the market and rank ordering them in terms of absolute value. Of course it might be of value to decrease the resolution of the series to get a more fitting view of reality. One may also want to make other adjustments. But the bottom line is this-- there are some stocks out there which have correlations over the past year that are literally up around 60%. This is ridiculously high. One will also find that certain industries just happen to correlate more than other industries. This has profound implications on our ability to make individual stock bets.
Why should I look at Beta? We look at Beta because our stocks tend to be positively correlated with the market. But if you actually do out the numbers, with daily resolution the absolute correlations are typically quite low. Betas of 1 or 2 or more are typically are a result of having a much higher relative vol.
Now imagine that you have a stock whose correlation with its industry is around 40 or 50%. Do I want to focus my attention on my one company? Perhaps, but from a risk management point of view, there are marked differences between this and a more statistically disperse industry.
Furthermore, correlation studies have implications on information gathering. And hedge effectiveness. But I will leave that up to my readers to think about.
posted by Dan McCarthy at
7:52 PM
|
0 comments
![]()
![]()
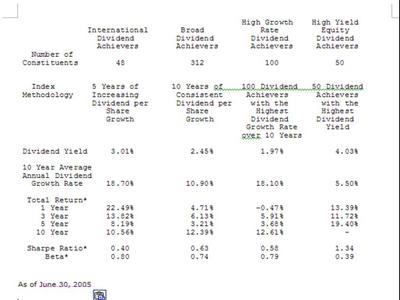 ... the historical performance of the newly created ETF's suck, unless I'm really missing something. The Sharpe for the flagship PEY knocks the freaking socks off of the three new ETF's. And at the same time, the historical Beta is around half that of the newbies! They are publicly announcing this themselves?
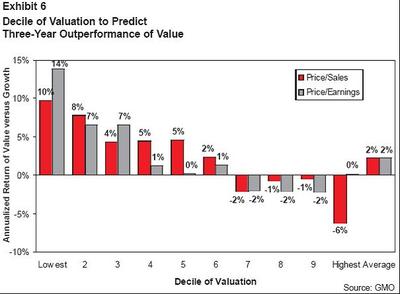
... the historical performance of the newly created ETF's suck, unless I'm really missing something. The Sharpe for the flagship PEY knocks the freaking socks off of the three new ETF's. And at the same time, the historical Beta is around half that of the newbies! They are publicly announcing this themselves?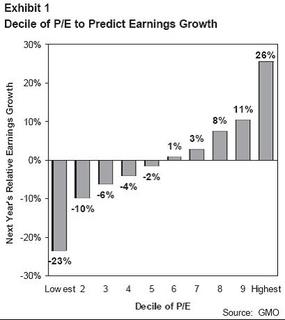 Fact #2: Value Stocks have indeed outperformed the market historically
Fact #2: Value Stocks have indeed outperformed the market historically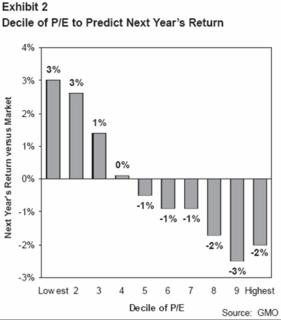 So what GMO did to dig into this a little more was compare the Russell 1000 Growth index versus the Russell 1000 Value index. The author assumes this to be a good proxy for value versus growth, so perhaps one might want to know exactly what the difference is between the two:
So what GMO did to dig into this a little more was compare the Russell 1000 Growth index versus the Russell 1000 Value index. The author assumes this to be a good proxy for value versus growth, so perhaps one might want to know exactly what the difference is between the two: