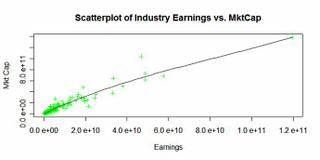
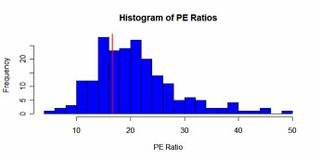
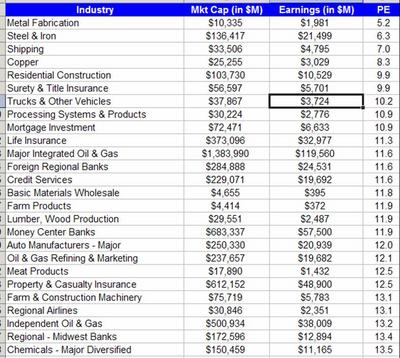
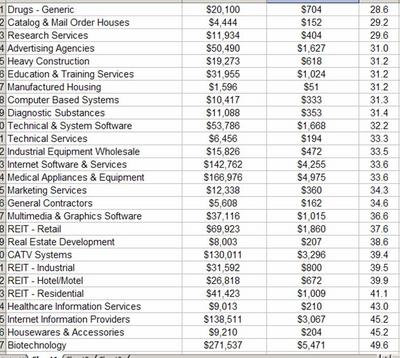
Taking a Look at Index Development Partners (IXDP.PK)Below I take a look at IXDP and how it fits in the ETF industry. I conclude that while it’s not a deep value investment, it at the least is an interesting stock. At its current valuation though this is kinda ridiculous, unless they do something non-ETF related. I start with a write-up I did back in April 2005 on the ETF industry in general with a focus on equity ETF’s and IXDP in particular. At the bottom I update the situation briefly.
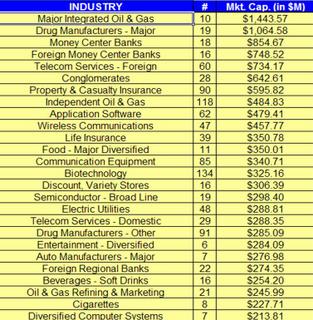
Size:Total ETF assets accounted for
$226.21 billion at the end of 2004, a 49.8% increase over the level of the previous year, according to the ICI.
Growth Prospects:Some industry experts said it will be hard for ETFs to keep up that kind of growth without new products. Unfortunately, most equity indexes are taken, which means that it will be difficult for ETF providers to come out with new domestic-equity funds. But new products will come. The difference is, some will probably have an actively managed flavor. The first steps towards actively managed ETFs are going to be enhanced indexing, which is where Index Development Partners (IXDP.PK) enters the picture.
Comparable:PowerShares Capital Management is one company which constructs enhanced indexes. It currently has seven new enhanced indexes based on Intellidex, a quantitative methodology, and now has around $500M in assets (PowerShares is planning to release a few new ETFs over the summer, some of which are based on Intellidex and some of which are going to be more ‘traditional’ they say). Rydex is involved with more passive strategies as well, but it has some pseudo-active strategies too. Its RSP S&P Equal Weight Index (rebalancing periodically) currently has ~$760M in assets.
Avenues for Growth:Industry analysts, however, stressed that while steady streams of new products are expected, they aren't necessary for the industry's assets to increase. While ETFs grew tremendously last year, total assets are small compared with the more than $8 trillion in mutual funds. If one holds the supply of wealth fixed, this means one big potential source of asset growth comes from taking sales away from the mutual fund industry.
The key to capturing more assets is education. Another potential key is the inclusion of ETFs on retirement platforms. Thus, growth is as much an exercise in marketing and business strategy as it is one in quantitative finance. Michael Steinhardt has specifically stated his interest in targeting all the important constituencies—brokerages, retirement platforms, individual investors, hedge funds, everyone.
My Spin:Investment strategies can be broken down into three broad categories—passive, pseudo-active, and active. The passive category has been largely exhausted. BGI was the victor in this field with its portfolio of iShares. There may still be some room for growth in passive bond and international strategies, but passive domestic equities are pretty much entirely covered. Active strategies are more the domain of hedge funds, which allow for complete investment flexibility, or other investment vehicles. Active strategies would be a difficult market to enter because it is highly competitive.
However the same isn’t necessarily true for pseudo-active strategies. What puts them in a unique competitive position is two-fold:
- They are active enough to “fine tune” passive index investment, potentially augmenting the risk-return characteristics of the investment with simple generally quantitative rules.
- They are passive enough to avoid the often onerous expenses charged by hedge fund and mutual fund managers alike.
There are currently two big players in the pseudo-active ETF market segment—PowerShares and Rydex (only some of Rydex’s portfolios however). While it is true that Barclays, Vanguard, and State Street hold the lion’s share of assets in the ETF market overall, pseudo-active strategies are fundamentally of a different type than the sort of ETFs currently being offered.
The Business Model:So this is the bottom line for ETF success as a business, as far as I can see it. Their main goal is to get huge amounts of investment in their funds so that they can collect the expense fee. ETF companies usually have a wide array of funds, which leads me to wonder what the costs/requirements are to registering an ETF. Whatever the requirements are, by casting out a wide net of distinct ETF’s, the ETF companies can get many disparate investment groups to invest in their products who wouldn’t have done so otherwise. The shotgun approach is probably a solid way to grow assets in the long run.
Cases in point:
- Macro hedge funds and quant funds are heavy players of SPX and other passive index ETF’s, for obvious reasons. Liquidity is already huge so ETF’s are in some ways able to capture the oft cited “hedge fund wave.”
- Hedge funds and individual investors can make sector specific bets with iShares, so BGI has created a ton of sector specific iShares.
- Individual investors wanting broad exposure to the markets without (1) getting charged like crazy for investing in many disparate stocks, and (2) needing to do DD on what stocks lead to the most “representative” mix to get proper diversified exposure.
- Retirement planners can just tuck money away in ETF’s instead of more expensive mutual funds, or more risky actively managed investments.
Expense Ratio Case Study—Rydex:Rydex generates revenues daily from its expense fee. As an example, take the Rydex equal-weighted S&P tracker (RSP). It has $765M under management and charges 40bps in the following way—Monday through Thursday count as 1 day, and Friday counts as 3. So they get .4%/365 of total assets on Monday through Thursday, and 1.2%/365 on Friday. So that fund generates around $3M in revenues annually, spread evenly throughout the year. Not much, but first of all, Rydex has $10B under management. Also, just imagine Barclays with its $110+B in assets, charging more than normal (the majority charge around 70bps), pulling in a steady $770M. Granted, they probably need to spend a good amount on transaction costs, but for crying out loud, they are doing passive indexing, and SPY is able to charge a meager 11bps! I would be surprised if they are paying more than 15bps, because even the SPY is generating a profit. This would mean that with the bulk of Barclay’s iShares, they are probably making around 55bps, implying pre-tax profits on the order of $605M.
There is one other cost which should be mentioned, licensing fees. When a company launches an ETF tracking a particular index, say the S&P, the ETF company will have to enter into a licensing agreement with S&P. This cost will probably be in terms of basis points. Vanguard ran into problems because of this back in 2001, as it was first launching its VIPER ETFs, which were referenced off of the S&P500. They believed that their existing agreements with S&P were enough, and further licensing agreements weren’t needed. S&P disagreed. Having a cheap expense ratio was of crucial importance to Vanguard, which is why this point ended up being hotly contested—Vanguard didn’t want to have to mark up their expense ratio by another handful of basis points.
Now things are quite different for enhancement strategies, because their stated goal is not solely to be representative of an index, or to have a broad exposure to something or other. If all you wanted was an ETF which has broad exposure to something or other, there is probably a passive ETF trading with a cheaper expense ratio right now. The draw to enhancement strategies lies in the potential for the 100-200bp potential upside relative to the reference index, accepting the sad fact that the expense ratio will probably be higher than their passive counterparts. Before I go into potential markets, it’s probably of value to do some back of the hand valuation calculations using PowerShares, the only true enhancement-focused comparable in the market right now, as a comparable. PowerShares was founded in August 2002. It now has around $500M in assets and 11 publicly traded funds. Its 2 oldest funds are less than 2 years old. Bond hopes to have between $2B and $3B by year’s end. Similar to IXDP, PowerShares received $10M in venture capital this year. PowerShares charges a maximum expense ratio of .6% (yet again implying big profits to Barclays).
IXDP now has a market cap of $10M. Assume that it makes a 40bp spread on {expense ratio – transaction costs}, an estimated 15bps below Barclays. Taking a look at operating expenses, before they stopped filing they were incurring around $310k in costs per quarter, or $1.24M at that run rate. Those are all probably research costs. When things start getting interesting, they will also be incurring a lot more business expenses—flying from place to place, lobbying to get advertising or to get on one platform or another—so the past is not a good predictor of the future in this case. Let’s say $3M steady state operating expenses just to throw out a number. If the above assumptions are true, they will need to have $750M under management to break even. $1B under management implies $1M in pre-tax profit. $10B implies $37M in pre-tax profit. Using PowerShares as a rough guideline, if IXDP successfully releases a few strong indices, it could hit $1B in a couple of years. IXDP has some superstar backing—the star power of the likes of Steinhardt, Steinberg, and Professor Siegel will be a plus when it begins marketing.
So the big question is what constituents would want to get involved with enhancement indices. I have a fundamental belief (as a pseudo-efficient markets believer?) that mutual fund money will slowly begin turning to ETF’s, so I believe there will be money flow for good strategies in the coming few years. Beyond that, it’s probably helpful to consider money flow from the various market participants:
- I don’t see why anyone would short an enhanced index. If people were, I would start getting worried. So this eliminates all shorts (as a funny point of comparison, PowerShares touts that it can be sold short on a down tick—great…)
- If costs are low, if the fund still retains its ability to track the S&P or any important index, and if liquidity is high, IXDP’s indices could get a lot of long money. If the above assumptions are true, then IXDP had better get portfolios out for all major indices!
- Steinhardt’s stated goal is 100 to 200bps over a reference index in the long run. This is too small for a long short after interest, so don’t expect anyone to put that trade on.
- It might be difficult to convince retirement platforms to consider IXDP because of the uncertainty associated with any form of active management.
I see big upside in Professor Siegel’s and Steinhardt’s ability to convince people that IXDP’s portfolios will be able to outperform the market on a consistent basis. Then anyone who wants to go long “the market” should consider IXDP’s portfolios as an alternative to its more traditional counterparts (ie. QQQQ, SPY).
UpdateSince the time of writing the prior post, a few things have changed.
- IXDP is changing its name to WisdomTree Investments, Inc.
- The stock is now trading at 3.95, and has just completed another round of equity financing. It now has 94M shares, implying a market cap of $371.3M. Siegel and Steinhardt were among the buyers. Steinhardt's cash infusions make me feel a little more comfortable that this thing won't go under.
- They’ve brought on board a few more people—Ray DeAngelo as the director of ETF Distribution, Michael Jackson as the new Director of Fund Services, and Marc Ruskin as the new CFO. They seem to have some pretty solid credentials. Finally, for those who have been paying attention, Wharton grad Jeremy Schwartz appears to have gotten a promotion. He is now a senior analyst at the fund.
Putting it all together, things are quite a bit different from the way they were.
Name Change:The fact that the company is changing its “strategic focus” from developing indices to being an asset manager interests and troubles me. Maybe it’s just me, but “asset manager” sounds quite… active. Perhaps more so than I would hope from a company whose prior investment thesis was built on the notion of creating a ‘small protected niche’ in the ETF space, creating and sponsoring innovative ETF’s. Does this imply that things are simply going so well on the index creation side that they are now focusing on higher goals without compromising the quality of their indices? From what I’ve seen and heard, this does NOT seem to be the case. But perhaps I’m reading too much into “asset manager”—perhaps they are just reinforcing the fact that ETF’s are a great asset management product for individual investors.
Market Cap:This thing is getting huge on no earnings. With the new full-time employees, my estimate of steady state expenses is probably on the low side. On the upside, it should be noted that in the latest equity issuance, Professor Jeremy Siegel and Michael Steinhardt were investors, although just how much wasn’t disclosed. For Steinhardt of course, this is peanuts. Even if he bought all of the 5.77M issued shares, that would amount to 10% of his existing stake. Steinhardt purchased his stake out of an equity issuance of 56.25M shares at $.16 and ended up with a 65.2% interest in the company (a 2370% return in 10 months... he hasn't lost his touch!).
Re-Evaluating Costs: Costs prior to the discontinuation of their filings was on the order of $1.2M. I had allocated around $1.8M in possible future steady state annual expenses. With the addition of 4 executives and still nothing out yet, I could very well be undershooting it, because they haven’t had to build any infrastructure yet. While I have the utmost faith in Jeremy Siegel and Jeremy Schwartz, in all likelihood I expect they’ll need to hire a few more research assistants. If they do get an ETF off the ground, something tells me they’ll also need some more operations people. I’m tempted to peg expenses at around $4M to $5M. This implies they’ll need anywhere from $1B to $1.25B to break even. If PowerShares is any indication, a successful ETF or two could put them at around $1B within the next couple of years. $2B would put them at $3M to $4M in pre-tax profits. With a market cap of $371M, I am not too pleased.
Open VariablesStar Power: One open variable in all this of course is the star power of the management team and the experience of new executives. PowerShares is a bunch of people cooped up in a room in Chicago with seemingly few connections. WisdomTree will have far fewer frictions conditional on their release of a solid product.
Registration Frictions: From what I've heard from competitors, it is no easy process to obtain sponsorship of an index, taking upwards of 2 years. There are only around 7 companies with proper registration. Even assuming that IXDP has an index right now and has already filed, this would be somewhat damning. Perhaps IXDP has a work-around, but for now this should be a further point of caution.